
はじめに
こんにちは!タリーです☕️!
私は毎朝、色々なテックブログを漁るのが日課です。
しかし、記事を読んでいると、横の「オススメ記事」が気になったり、
文中の知らない用語を調べているうちに「あれも気になる、これも気になる...」と、
気づけばブラウザのタブがとんでもない数になっています。
結局、「本来読みたかった記事すら読めていない」「ただ時間を溶かして脱線してしまった」 ということが、多々ありました。
そんな時、外資系 IT エンジニアの京平さんが実践されている
「GitHubで人生を管理する」
という動画に出会いました。
動画の中で紹介されていたのが、Claude Code Skills を活用した情報収集の仕組みです。(15分あたりから)
具体的には、特定のコマンドを実行するだけでトレンド記事や自分の気になる分野の記事だけをAIが厳選し、それを Markdown ファイルとして出力させるというものでした。
「これだ!」と思い、私も自分専用の収集システムを作成してみました。
結果
朝の調べ物で脱線することが劇的に減り、本当に必要な情報だけをじっくり読めるようになったので、
その仕組みを共有します!
Claude Code Skills とは?
一言で言うと...
「自分専用の自動化ワークフローを /コマンド 一つで実行可能にする、Claude Code の拡張機能」 です。
単に AI とチャットするだけでなく、
- 「スクリプトを実行して情報を取ってくる」
- 「取得した情報を特定のルールで選別する」
- 「決まったフォーマットでファイルに書き出す」
といった一連のワークフローを、/trend のような短いコマンド一発で実行できるのが最大の魅力です。
次のセクションからは、具体的な構築手順についてお話しします。
構築手順
それでは、具体的にどのような手順でこの仕組みを構築したのかを解説します。
基本的には「情報の取得スクリプト」を用意し、それを Claude Code の「説明書(CLAUDE.md)」で紐付けるだけですが、大別すると4つのステップです!
※Skillsに関しても Claude Code に作成してもらっています。
1. ディレクトリ構成
リポジトリ内が散らからないよう、技術トレンド用の仕組みは tech-trend/ ディレクトリに集約しました。
また、Claude Code がスキルとして認識するための定義ファイルを .claude/skills/ 配下に配置します。
これで /trend コマンドで実行する準備ができました。
.
├── CLAUDE.md # リポジトリ全体のルールと選別基準
├── .claude/
│ └── skills/
│ └── trend/
│ └── SKILL.md # /trend コマンドの定義
└── tech-trend/
├── scripts/
│ └── fetch-news.ts # 情報取得用スクリプト (TypeScript)
└── 00_DailyNews/ # 生成された Markdown の保存先
2. 情報取得スクリプトの作成
まずは、各テックブログの RSS や API から情報を引っこ抜くスクリプトを作成します。
/**
* fetch-news.ts
*
* 各種 RSS / Atom フィードから記事を取得し、JSON 配列として標準出力に出力する。
* 実行: npx tsx fetch-news.ts
*
* 出力形式:
* [{ title, url, source, lang, date }, ...]
*/
interface Article {
title: string;
url: string;
source: string;
lang: "ja" | "en";
date: string;
}
// ---------- フィード定義 ----------
const FEEDS: { url: string; source: string; lang: "ja" | "en" }[] = [
// 日本語
{
url: "https://b.hatena.ne.jp/hotentry/it.rss",
source: "はてなブックマーク",
lang: "ja",
},
{ url: "https://zenn.dev/feed", source: "Zenn", lang: "ja" },
{
url: "https://zenn.dev/topics/react/feed",
source: "Zenn(React)",
lang: "ja",
},
{
url: "https://zenn.dev/topics/typescript/feed",
source: "Zenn(TypeScript)",
lang: "ja",
},
{
url: "https://qiita.com/popular-items/feed.atom",
source: "Qiita",
lang: "ja",
},
{
url: "https://qiita.com/tags/React/feed.atom",
source: "Qiita(React)",
lang: "ja",
},
{
url: "https://qiita.com/tags/TypeScript/feed.atom",
source: "Qiita(TypeScript)",
lang: "ja",
},
// 英語
{ url: "https://hnrss.org/frontpage", source: "Hacker News", lang: "en" },
{ url: "https://dev.to/feed", source: "dev.to", lang: "en" },
{
url: "https://dev.to/feed/tag/react",
source: "dev.to(React)",
lang: "en",
},
{
url: "https://aws.amazon.com/about-aws/whats-new/recent/feed/",
source: "AWS News Blog",
lang: "en",
},
{ url: "https://go.dev/blog/feed.atom", source: "Go Blog", lang: "en" },
{ url: "https://www.echojs.com/rss", source: "Echo JS", lang: "en" },
];
// ---------- XML パーサ ----------
/** RSS <item> からフィールドを抽出 */
function parseRssItems(
xml: string,
source: string,
lang: "ja" | "en"
): Article[] {
const items: Article[] = [];
const itemRegex = /<item[\s>]([\s\S]*?)<\/item>/gi;
let match: RegExpExecArray | null;
while ((match = itemRegex.exec(xml)) !== null) {
const block = match[1];
const title = extractTag(block, "title");
const link = extractTag(block, "link") || extractAttr(block, "link", "href");
const pubDate = extractTag(block, "pubDate") || extractTag(block, "published") || extractTag(block, "dc:date");
if (title && link) {
items.push({
title: decodeEntities(title),
url: link.trim(),
source,
lang,
date: normalizeDate(pubDate),
});
}
}
return items;
}
/** Atom <entry> からフィールドを抽出 */
function parseAtomEntries(
xml: string,
source: string,
lang: "ja" | "en"
): Article[] {
const items: Article[] = [];
const entryRegex = /<entry[\s>]([\s\S]*?)<\/entry>/gi;
let match: RegExpExecArray | null;
while ((match = entryRegex.exec(xml)) !== null) {
const block = match[1];
const title = extractTag(block, "title");
const link =
extractAttr(block, "link", "href") || extractTag(block, "link");
const published =
extractTag(block, "published") || extractTag(block, "updated");
if (title && link) {
items.push({
title: decodeEntities(title),
url: link.trim(),
source,
lang,
date: normalizeDate(published),
});
}
}
return items;
}
function extractTag(xml: string, tag: string): string {
const re = new RegExp(
`<${tag}(?:[^>]*)>\\s*(?:<!\\[CDATA\\[)?([\\s\\S]*?)(?:\\]\\]>)?\\s*<\\/${tag}>`,
"i"
);
const m = re.exec(xml);
return m ? m[1].trim() : "";
}
function extractAttr(xml: string, tag: string, attr: string): string {
const re = new RegExp(`<${tag}[^>]*\\s${attr}="([^"]*)"`, "i");
const m = re.exec(xml);
return m ? m[1].trim() : "";
}
function decodeEntities(str: string): string {
return str
.replace(/&/g, "&")
.replace(/</g, "<")
.replace(/>/g, ">")
.replace(/"/g, '"')
.replace(/'/g, "'")
.replace(/&#x([0-9a-fA-F]+);/g, (_, hex) => String.fromCodePoint(parseInt(hex, 16)))
.replace(/&#(\d+);/g, (_, code) => String.fromCodePoint(Number(code)));
}
function normalizeDate(raw: string | undefined): string {
if (!raw) return new Date().toISOString().slice(0, 10);
try {
return new Date(raw).toISOString().slice(0, 10);
} catch {
return new Date().toISOString().slice(0, 10);
}
}
// ---------- フェッチ ----------
async function fetchFeed(
feedUrl: string,
source: string,
lang: "ja" | "en"
): Promise<Article[]> {
try {
const res = await fetch(feedUrl, {
headers: { "User-Agent": "obsidian-memo-tech-trend/1.0" },
signal: AbortSignal.timeout(10_000),
});
if (!res.ok) {
console.error(`[WARN] ${source}: HTTP ${res.status}`);
return [];
}
const xml = await res.text();
// Atom or RSS を判定
const isAtom = /<feed\b/i.test(xml) || /<entry\b/i.test(xml);
return isAtom
? parseAtomEntries(xml, source, lang)
: parseRssItems(xml, source, lang);
} catch (err) {
console.error(`[WARN] ${source}: ${(err as Error).message}`);
return [];
}
}
// ---------- メイン ----------
async function main() {
const results = await Promise.all(
FEEDS.map((f) => fetchFeed(f.url, f.source, f.lang))
);
const articles: Article[] = results.flat();
// URL で重複排除
const seen = new Set<string>();
const unique = articles.filter((a) => {
if (seen.has(a.url)) return false;
seen.add(a.url);
return true;
});
process.stdout.write(JSON.stringify(unique, null, 2) + "\n");
}
main().catch((err) => {
console.error(err);
process.exit(1);
});
※ 私はZenn,Qiiita,Hacker Newsなどを検索していますが、お好みのものに変更してください🙇
3. CLAUDE.md で「選別ルール」を教える
次に、リポジトリルートの CLAUDE.md に、AI が記事をどう選別すべきかの基準を書き込みます。
ここが 「自分専用」 になる肝の部分です。
## 技術トレンド収集(/trend, /digest)— 選別ルール
`/trend` や `/digest`で技術情報を収集・選別するときは、このセクションのルールに従う。
### 興味関心キーワード(優先して拾う)
- フロントエンド: React, Next.js
- クラウド・インフラ: AWS
- バックエンド・言語: TypeScript(Express, NestJS), Go, Java
### 選別の考え方
- 技術記事: How-to、チュートリアル、ベストプラクティス、リリースノートなど。
- 概念的・議論系: 「React 不要論」「〇〇のトレンド」「エコシステム論」など、技術にまつわる論争・思潮・トレンドの記事も積極的に拾う。技術的な手順だけでなく、「なぜ・どう考えるか」のトピックも含める。
### 選別ルールの更新
- 日々の対話で「この記事は要らない」「この種は毎回入れて」などフィードバックがあったら、この「選別ルール」セクションを適宜更新する。CLAUDE.md のこの部分を編集して、選別基準を反映すること。
### 取得する情報源(テックブログ・RSS 等)
| 種別 | 情報源 | 備考 |
|------|--------|------|
| 日本語 | はてなブックマーク(テクノロジー) | ホットエントリー it |
| 日本語 | Zenn | トレンド・トピック別フィード |
| 日本語 | Qiita | 人気・タグ別フィード |
| 英語 | Hacker News | フロントページ・API |
| 英語 | dev.to | 全体 or タグ(例: react) |
| 英語 | AWS News Blog | 公式 RSS |
| その他 | React 公式ブログ・Go 公式ブログ等 | RSS があれば追加可 |
※ 私は興味関心キーワードはReact、Next.js、AWSなどを記述していますがお好みのものに変更してください🙇
4. スキルの登録
最後に、
.claude/skills/trend/SKILL.md
を作成して、コマンドを登録します。
# /trend Skill
1. `npx tsx tech-trend/scripts/fetch-news.ts` を実行して生データを取得する。
2. 取得した JSON データを CLAUDE.md の選別ルールに従ってフィルタリングする。
3. 結果を `tech-trend/00_DailyNews/YYYY-MM-DD.md` に保存する。
4. ファイル冒頭には Obsidian 用のプロパティ(date, tags: [daily-news])を付与すること。
実際に出力される様子
/trend がSkillsに登録されていることが確認できました!!!!
記事を出力した日は2026年3月10日なので2026-03-10.mdファイルが作成されれば成功です!↓
/trendを実行してしばらく待ちます。(30秒ほど)
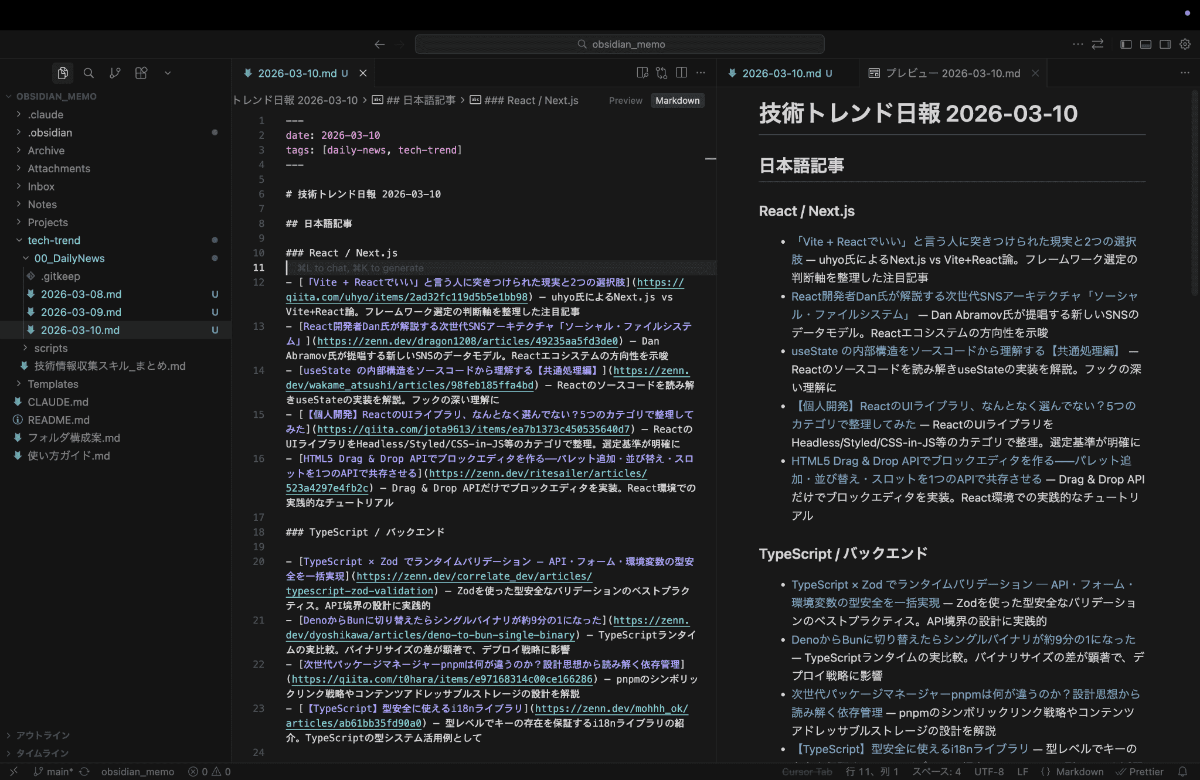
すると2026-03-10.mdファイルが自動で作成され記事の選出もされました!↓
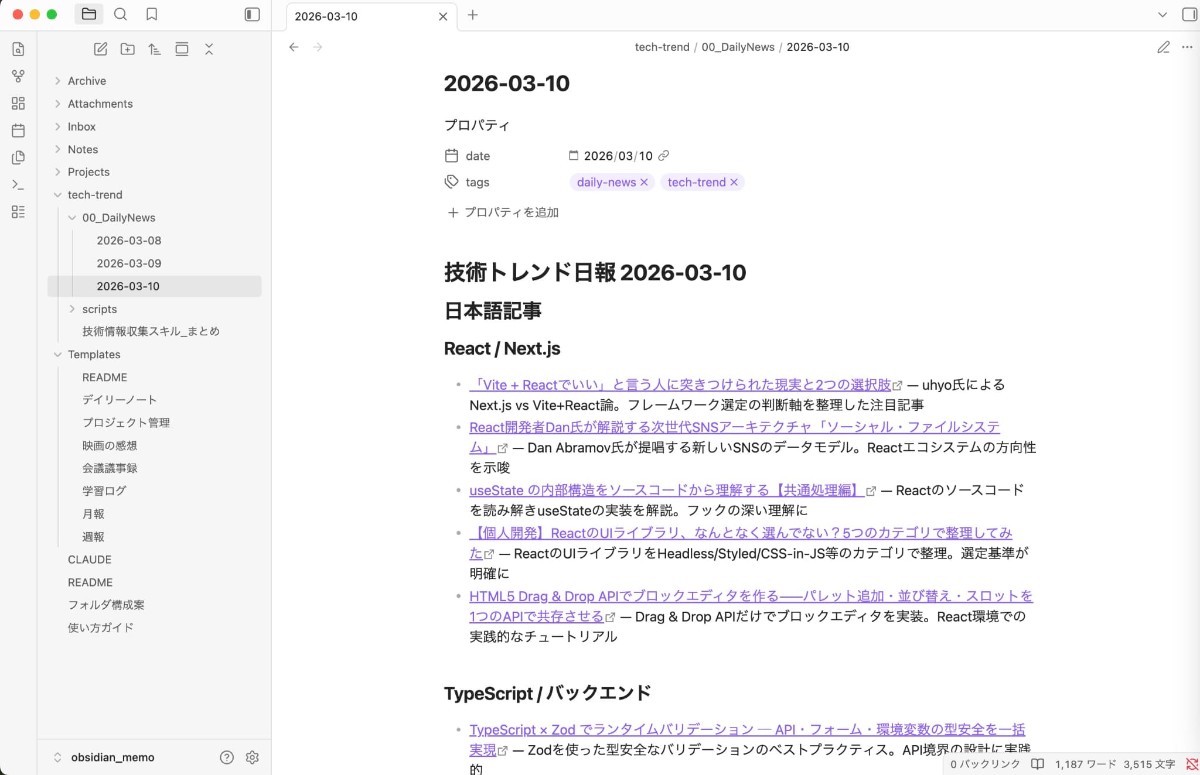
私はこのリポジトリをObsidianと紐づけているので Markdown ファイルをObsidian上で確認することができます!↓
まとめ
この仕組みを導入してから、朝のルーティンが劇的に変わりました。
自分に合った記事を検索する時間はコーヒーを淹れる時間へと変わり、コーヒーを飲みながらブログを読むという時間になりました☕️
「記事を探す時間ないよ〜」と言う方是非お試しください! 自動化することで驚くほど時間短縮されます!!
他にも便利なSkillsなど紹介されている方がいるので、どんどん真似していきたいと思います!!
最近は
/laundry
で洗濯とかしてくれたらなーーー、とか考えています笑
皆さんも良いClaude Code Lifeを👋
おすすめ記事






コメント
コメントを読み込み中...